Tired of getting
blocked? Start leveraging
our Scraping API.
ScrapeNetwork handles the proxies, browsers, and captcha’s returning you html from any webpage with a simple api call. Get started today!
30 Day Free Trial
No Credit Card Required
5,000 Free API Calls
30 Day Free Trial
No Credit Card Required
5,000 Free API Calls
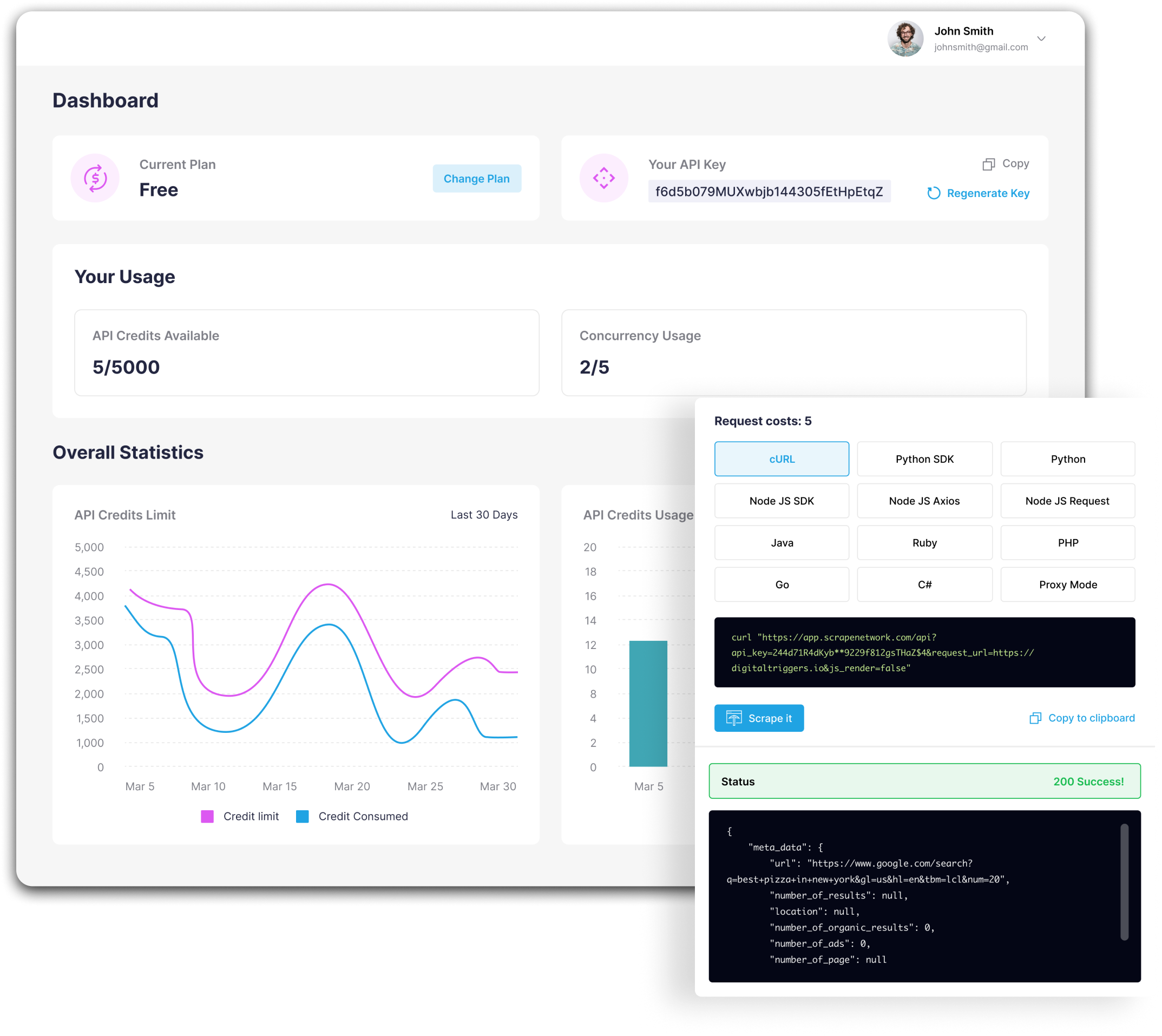
Data Extraction by our
own Builder
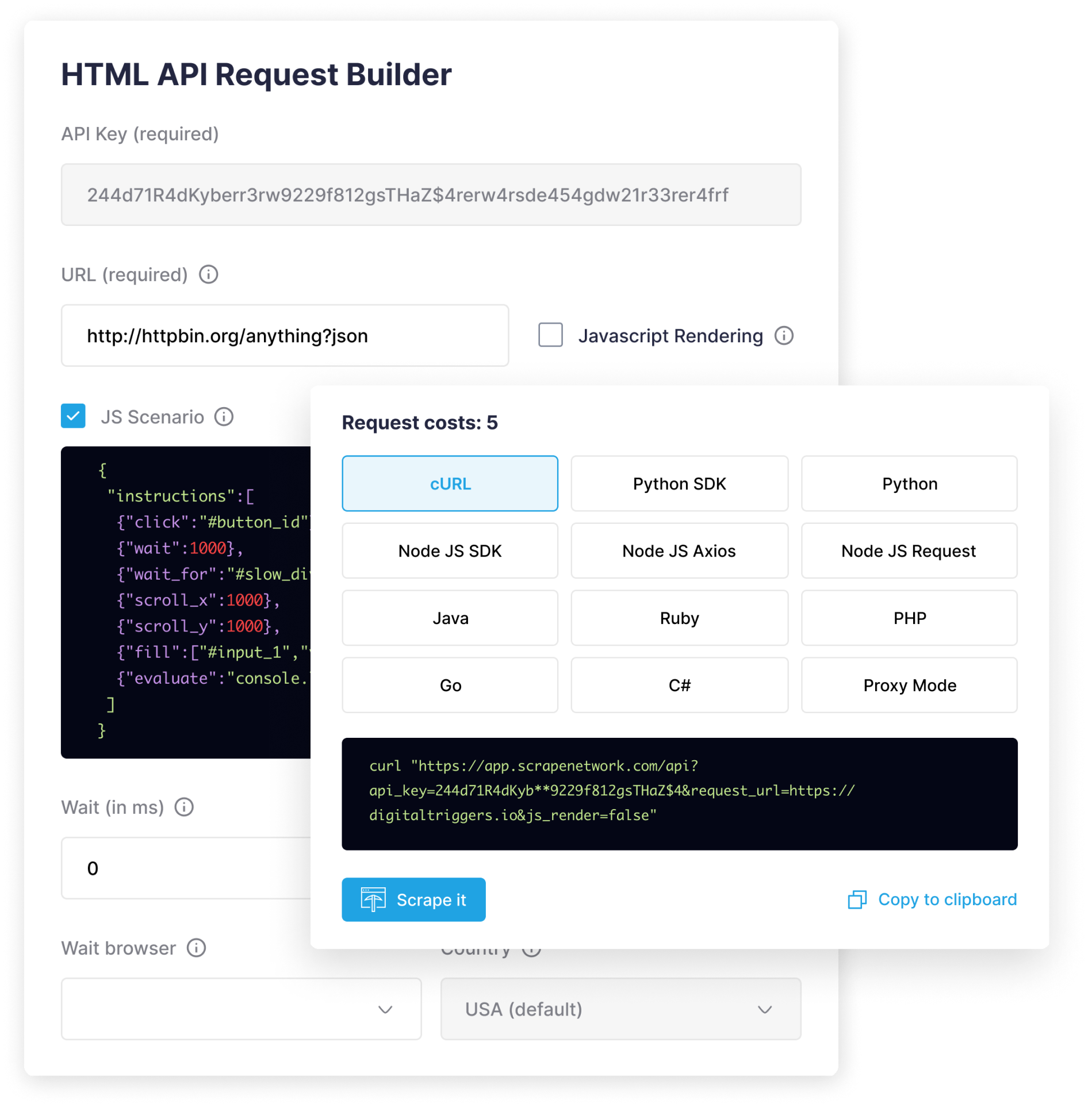
HTML API Request Builder
Easily construct complex HTML API requests with our intuitive HTML API
Request Builder. Our tool streamlines the process of crafting HTML requests,
allowing developers to specify headers, parameters, and payloads effortlessly.
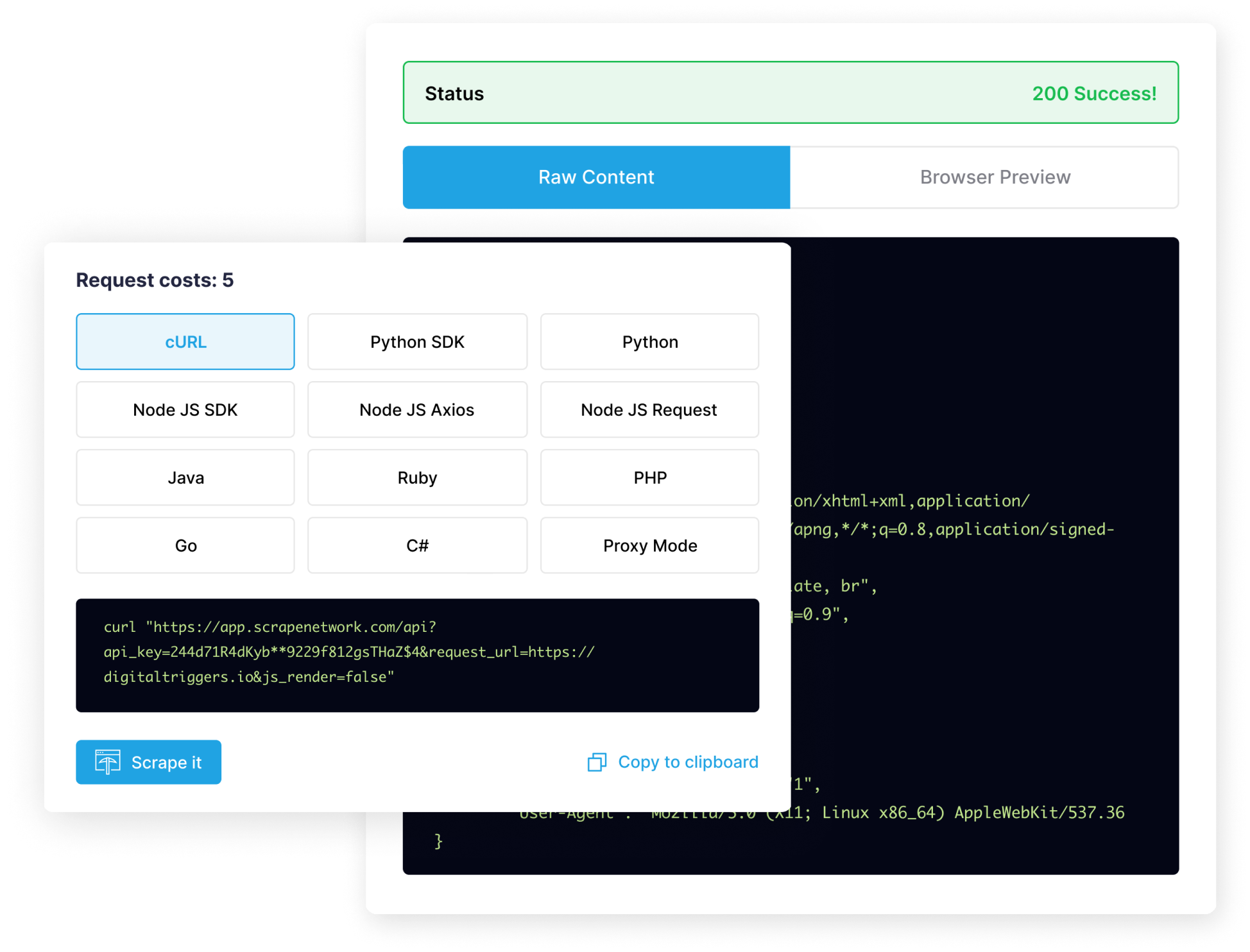
Our web scraping solution prioritizes efficiency by swiftly extracting data from target websites, minimizing processing time and maximizing productivity. With streamlined workflows and optimized algorithms, we ensure that every scraping task is executed with precision and speed, allowing you to access the information you need promptly.
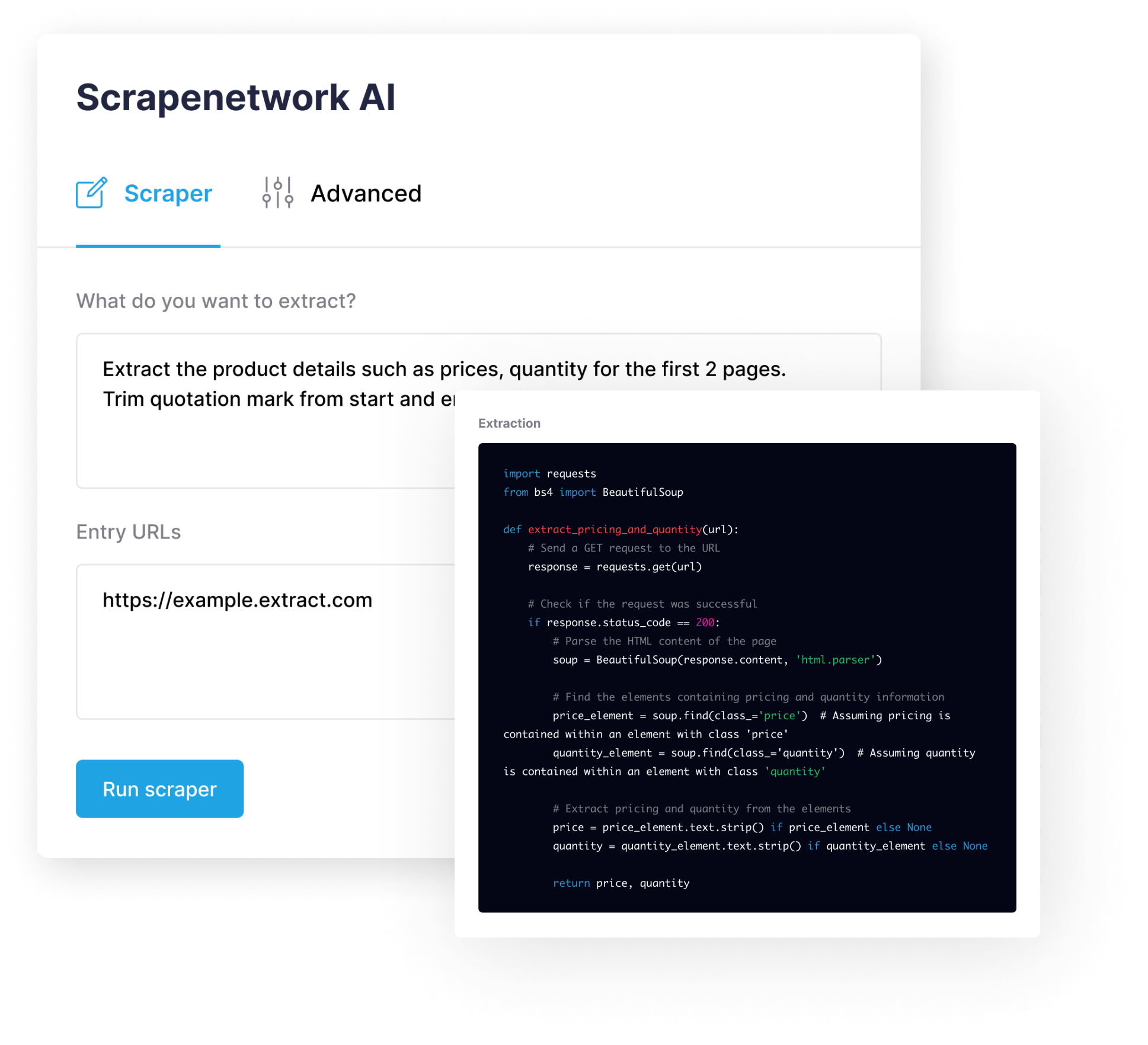
Just describe the data you need, and we will take care of the tedious work, such as proxy rotation, pagination, prompt engineering, and more.
Scrapenetwork AI combines the practicality of language models with the powerful features of a traditional scraper such as pagination and proxy rotation.
Scrapenetwork is the easiest website scraper. You don’t need to know how to code. Just fill-out what info you want to scrape.
Real Browsers
You won’t be blocked. We use real browser instances to perform fast but human web scrapings, resulting in a much lower block ratio.
Screenshots
Need a screenshot of that website and not HTML? You can do this very easily with our screenshot feature. We also support full page and partial screenshots!
Flexible Scheduler
Scrape even when you are sleeping or not in your computer. You can set up any kind of schedule to perform your scrapings just when you need it.
Integrated with parser
Sometimes it will be impossible to scrape the data from websites in the format you need. Using Scrapenetwork, you can parse and format the data just the way you want.
API
All plans come with access to an API. With the API, you can integrate Scrapenetwork it with your own application or scheduling system.
Scraper vs Scrapenetwork
This is how Scrapenetwork compares with coding a site scraper from scratch
MANY HOURS
Build a scraper
Spend hours to code the web data extraction logic.
Find a way to schedule and run your web scraper in your system.
Research, set up and maintain proxies to prevent being blocked by the websites.
Review, parse, and clean the scraped information in order to have usable data.
Add more complexity building integrations or manually saving the information.
Adding more integrations to share the data or create reports.
The website changed, or other data is needed: Another code scraper has to be built.
A FEW MINUTES
With Scrapenetwork
Paste a URL and select the web elements you want to scrape.
Easily schedule the scraper using a visual builder.
Proxies will be automatically managed and rotated for you in every single request.
Assign a parse rule or cleaning action to any selector you need to process.
Unlimited storage to save your website scrapers results and data collection.
Lots of integrations to interact with your databases.
No coding skills needed. Find selectors using our browser extension.
Connect with Ease: Integrating Web
Scraping into Your Workflow